flowchart TD
A[Historical Prices & Features] --> B[Feature Engineering]
B --> C[Past Returns and Variances]
C --> D[Latent Volatility Sampling]
D --> E[Log Return Sampling]
E --> F[Reconstruct Price Path]
F --> H[Output Price Path Simulation]
GARCH-inspire latent volatility model
Note
Generative AI was used to fix grammar in the writing. The rest is done by me.
In the previous post I built a very simple model to demonstrate how log return dynamics can be learnt from previous noisy observations of observed returns. The real problem of that approach was that variance was assumed to be something observed, whereas it is clear that variance is not something we measure directly.
We do not measure log returns either, but those were sampled, so we assumed we do not know them. In this post I’m actually going to switch to modelling latent volatility, which is supposedly a better way to build this sort of model.
Running a bit ahead of myself, I do think that this sort of modelling leads to better and more reasonable models, but quantifying these statements is something we will deal with later on.
This articles describes in details the following flow:
Data loading
We start by loading the data, and examining the returns, log-return distribution, as well as variance plots. The dataset we are using today contains heating oil prices from 2010 until May, 2025. The dataset was pulled from investing.com.
source_df = (
pl.read_csv(
"./data/heating_oil.csv",
infer_schema_length=0,
dtypes={"Price": pl.Utf8},
columns=["Date", "Price"],
)
.with_columns(
pl.col("Date").str.to_date(format="%m/%d/%Y"),
pl.col("Price").str.replace_all(",", "").cast(pl.Float64),
)
.rename({"Date": "date", "Price": "price"})
.with_columns(
ret=pl.col("price") / pl.col("price").shift(1),
)
).sort("date")
source_df.head()/var/folders/8s/q13s1_m56g3b3k_1fmdrwn_80000gn/T/ipykernel_20067/1155920622.py:2: DeprecationWarning: The argument `dtypes` for `read_csv` is deprecated. It has been renamed to `schema_overrides`.
pl.read_csv(
shape: (5, 3)
| date | price | ret |
|---|---|---|
| date | f64 | f64 |
| 2010-04-05 | 2.2825 | 0.998775 |
| 2010-04-06 | 2.2853 | 1.010703 |
| 2010-04-07 | 2.2611 | 1.007396 |
| 2010-04-08 | 2.2445 | 1.000401 |
| 2010-04-09 | 2.2436 | 1.002771 |
source_df = DataLoader().load_data("data/ng_daily.csv")
source_df
shape: (7_060, 3)
| date | price | ret |
|---|---|---|
| date | f64 | f64 |
| 1997-01-07 | 3.82 | null |
| 1997-01-08 | 3.8 | 0.994764 |
| 1997-01-09 | 3.61 | 0.95 |
| 1997-01-10 | 3.92 | 1.085873 |
| 1997-01-13 | 4.0 | 1.020408 |
| … | … | … |
| 2025-02-04 | 3.25 | 0.984848 |
| 2025-02-05 | 3.22 | 0.990769 |
| 2025-02-06 | 3.31 | 1.02795 |
| 2025-02-07 | 3.32 | 1.003021 |
| 2025-02-10 | 3.48 | 1.048193 |
Feature extraction
The class below is implemented to ease off the data analysis and handling. It produces lagged features for returns and variances, as well as transforms the data so it is easier to feed into a model.
feature_engineer = FeatureEngineer(
transforms=[
LogReturn(source_field="ret", feature_name="log_ret"),
Variance(
source_field="price",
feature_name="var",
rolling_variance_window=2,
),
LogReturn(source_field="var", feature_name="log_var", requested_lag=0),
QuantileTransformer(
source_field="var", feature_name="var_quantile", requested_lag=1
),
],
n_shifts=3,
)
df_with_features = feature_engineer.create_features(source_df)
df_with_features.head()
shape: (5, 14)
| date | price | ret | log_ret | var | log_var | var_quantile | prev_log_ret_1 | prev_log_ret_2 | prev_log_ret_3 | prev_var_1 | prev_var_2 | prev_var_3 | prev_var_quantile_1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 |
| 1997-01-13 | 4.0 | 1.020408 | 0.020203 | 0.0032 | -5.744604 | 0.511527 | 0.082384 | -0.051293 | -0.005249 | 0.04805 | 0.01805 | 0.0002 | 0.905906 |
| 1997-01-14 | 4.01 | 1.0025 | 0.002497 | 0.0001 | -9.21034 | 0.0 | 0.020203 | 0.082384 | -0.051293 | 0.0032 | 0.04805 | 0.01805 | 0.511527 |
| 1997-01-15 | 4.34 | 1.082294 | 0.079083 | 0.05445 | -2.910472 | 0.915916 | 0.002497 | 0.020203 | 0.082384 | 0.0001 | 0.0032 | 0.04805 | 0.0 |
| 1997-01-16 | 4.71 | 1.085253 | 0.081814 | 0.06845 | -2.681652 | 0.929968 | 0.079083 | 0.002497 | 0.020203 | 0.05445 | 0.0001 | 0.0032 | 0.915916 |
| 1997-01-17 | 3.91 | 0.830149 | -0.186151 | 0.32 | -1.139434 | 0.984985 | 0.081814 | 0.079083 | 0.002497 | 0.06845 | 0.05445 | 0.0001 | 0.929968 |
sns.histplot(df_with_features, x="log_ret")
sns.histplot(df_with_features, x="ret")
plt.xlim([-1, 2])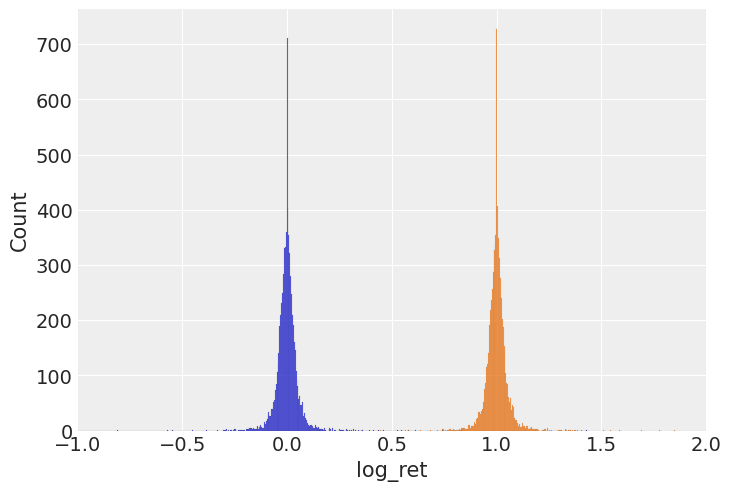
plt.figure(figsize=(16, 6))
sns.lineplot(df_with_features, x="date", y="price")
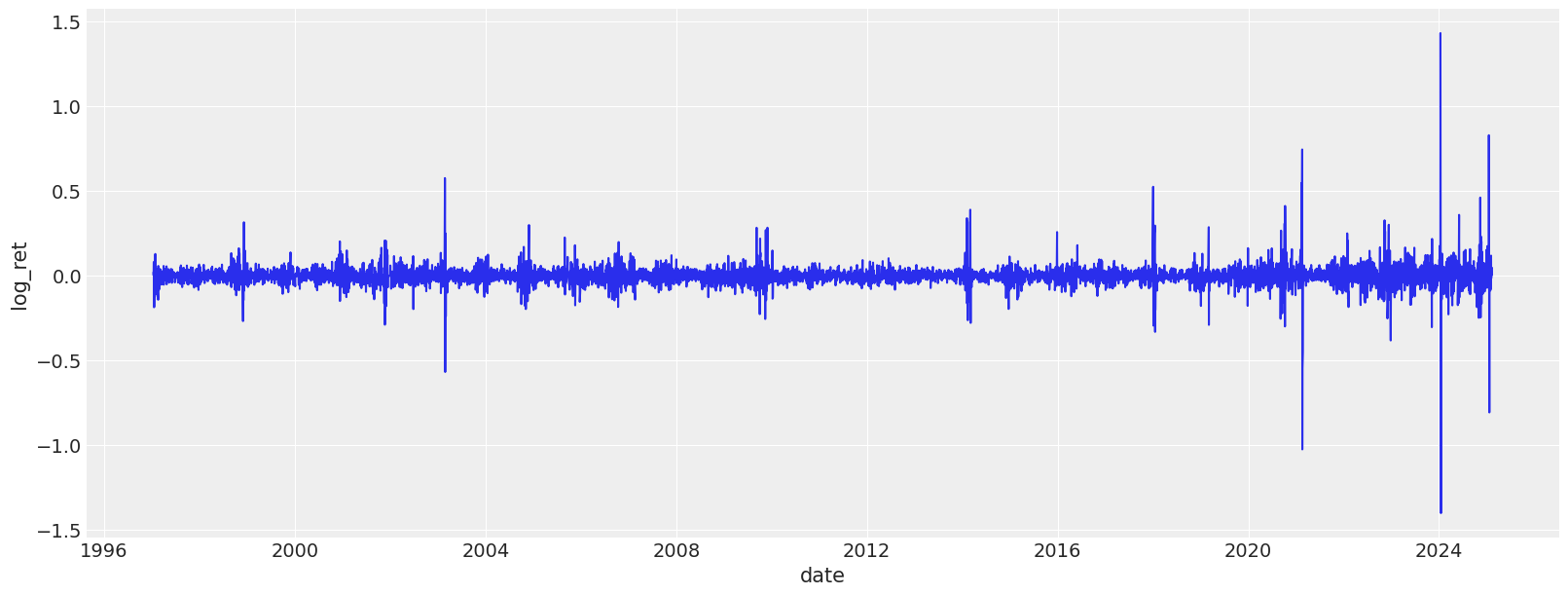
plt.figure(figsize=(16, 6))
sns.lineplot(df_with_features, x="date", y="log_ret")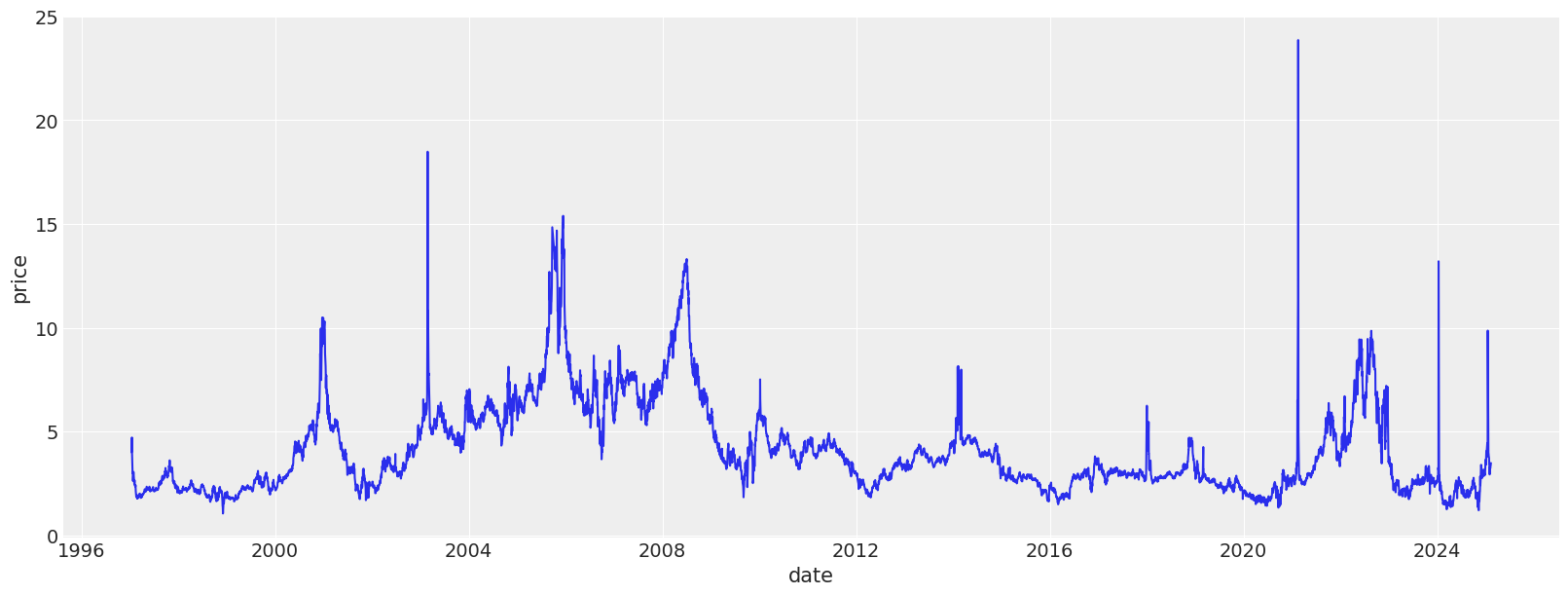
The model
I will now demonstrate how one can build a latent volatility model that can then be used to sample new observations in an autoregressive manner. The main change here is that the volatility is not a linear function anymore, like it used to be, but it is a latent variable sampled along with the log return. Still, a limitation remains for this model that we do condition our latent volatility on the observed noisy variable. Worth noting, that we assume a latent volatility variable per time step, meaning we will end up with a latent volatility variable that has the length of the original time series.
As before, the log return is sampled from Student T distribution so account for potentially heavier tails. Other than that, we still use Monte Carlo to build an idea for posterior distributions. Despite a relatively long time series, the below model sampling is quite efficient, so should converge fast.
# Cut-off point
T = 300
present_value_log_ret, present_value_log_var, present_value_test = (
df_with_features["log_ret"][:-T].to_numpy(),
df_with_features["log_var"][:-T].to_numpy(),
df_with_features["log_ret"][-T:].to_numpy(),
)
past_values_train, past_values_test = (
feature_engineer.to_numpy_dict(df_with_features[:-T]),
feature_engineer.to_numpy_dict(df_with_features[-T:]),
)garch_like_sample_vol_model
garch_like_sample_vol_model (value_log_ret:numpy.ndarray[typing.Any,numpy .dtype[+_ScalarType_co]]=None, log_var_value :numpy.ndarray[typing.Any,numpy.dtype[+_Scal arType_co]]=None, past_values:dict[str,numpy .ndarray[typing.Any,numpy.dtype[+_ScalarType _co]]]=None)
numpyro.render_model(
garch_like_sample_vol_model,
model_args=(
present_value_log_ret,
present_value_log_var,
past_values_train,
),
)
rng_key = random.PRNGKey(0)
rng_key, rng_key_ = random.split(rng_key)
# Run NUTS.
kernel = NUTS(garch_like_sample_vol_model)
num_samples = 2000
mcmc = MCMC(kernel, num_warmup=1000, num_samples=num_samples)
mcmc.run(
rng_key_,
present_value_log_ret,
present_value_log_var,
past_values_train,
)
mcmc.print_summary()
posterior_samples = mcmc.get_samples()
print(posterior_samples.keys())sample: 100%|██████████| 3000/3000 [00:01<00:00, 2140.04it/s, 11 steps of size 2.40e-01. acc. prob=0.92]
mean std median 5.0% 95.0% n_eff r_hat
b_var -7.02 0.00 -7.02 -7.02 -7.02 663.62 1.00
param_prev_var_quantile_1 2.09 0.00 2.09 2.08 2.09 625.89 1.00
Number of divergences: 0
dict_keys(['b_var', 'log_ret_var', 'param_prev_var_quantile_1'])Post-fitting checks
posterior_samples = mcmc.get_samples()
predictive = Predictive(
garch_like_sample_vol_model,
posterior_samples=posterior_samples,
return_sites=["log_ret"], # or whatever your observation site is called
)
rng_key, rng_key_ppc = random.split(rng_key)
ppc_samples = predictive(
rng_key_ppc,
present_value_log_ret,
present_value_log_var,
past_values_train,
)
prior_samples = Predictive(garch_like_sample_vol_model, num_samples=2000)(
rng_key,
present_value_log_ret,
present_value_log_var,
past_values_train,
)
idata = az.from_numpyro(mcmc, posterior_predictive=ppc_samples, prior=prior_samples)az.plot_trace(idata, var_names=["~^log_ret_var"], filter_vars="regex");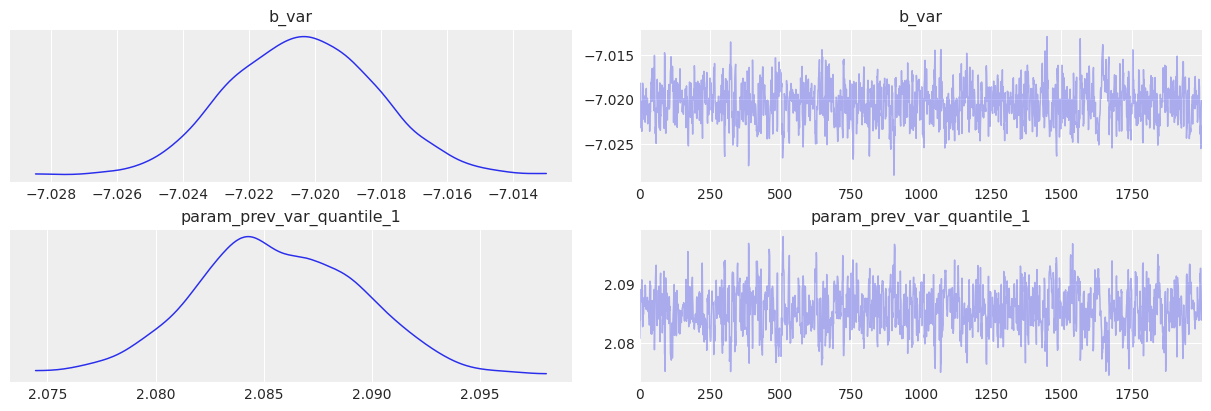
Future paths simulations
Finally, we are able to run the autoregressive simulation and look at the distribution of the final prices. Let’s look at the average sample error for each of the run id. We then can compare the average spread relative to the
simulator = Simulator(
model=garch_like_sample_vol_model,
feature_engineer=feature_engineer,
)
posterior_for_gen = {k: ps[0:1] for k, ps in posterior_samples.items()}
del posterior_for_gen["log_ret_var"]
starting_sim_df = source_df[-T - feature_engineer.n_shifts * 5 - 50 : -T]
all_runs = simulator.simulate_paths(
steps=30,
starting_sim_df=starting_sim_df,
posterior_samples=posterior_for_gen,
num_sims=200,
)
sns.lineplot(all_runs, x="date", y="price", hue="run_id")
plt.xticks(rotation=90);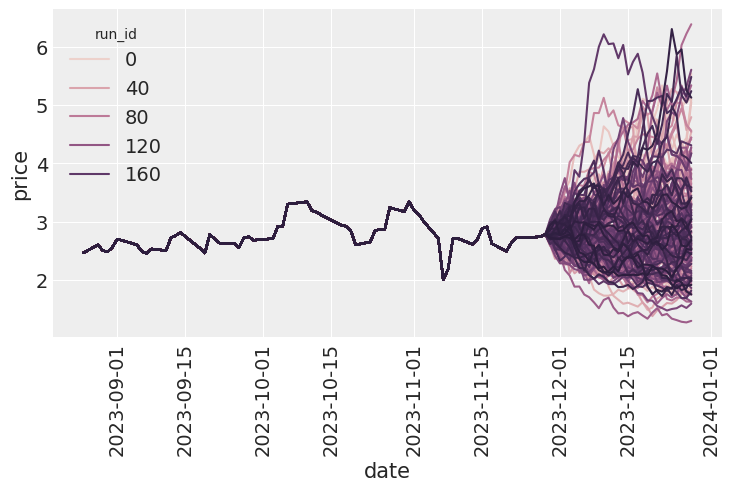
Model validation & predictive accuracy
I now turn my attention to testing the predictive power of the model. Posterior checks are good and fun, but the model is autoregressive in nature, so what needs to happen is we need to roll through out test set, simulate a distribution of forward looking prices, then do boxplots, with the predicted price distributions and the actual price inside those boxes. The purpose of this exercise is to see if the actual price tends to be within the range of prices that comes out of simulations.
In a no volatility perfectly almost perfectly predictable world, the boxes would be very tight around the actual observations, but realistically there is going to be a lot of wiggle room inside.
target_window = 7
simulator = Simulator(
model=garch_like_sample_vol_model, feature_engineer=feature_engineer
)
posterior_for_gen = {k: ps[0:1] for k, ps in posterior_samples.items()}
shifts = list(range(0, T, 10))
all_lasts = []
actual_prices = []
for ct, t in tqdm(enumerate(shifts), total=len(shifts)):
# print(f"Simulating shift {ct}/{len(shifts)}")
starting_sim_df = source_df[-T - feature_engineer.n_shifts * 5 - 50 + t : -T + t]
this_sim = simulator.simulate_paths(
steps=target_window,
starting_sim_df=starting_sim_df,
posterior_samples=posterior_for_gen,
num_sims=50,
)
last_prices = (
this_sim.sort("date") # Ensure dates are in correct order
.group_by("run_id")
.agg(pl.col("price").last()) # Get the last price for each run
.rename({"price": "final_price"})
.with_columns(pl.lit(ct).alias("run_id"))
)
actual_prices.append({"run_id": ct, "actual_price": source_df[-T + t]["price"][0]})
all_lasts.append(last_prices)
all_lasts = pl.concat(all_lasts)
actual_prices = pl.DataFrame(actual_prices)100%|██████████| 30/30 [00:25<00:00, 1.19it/s]sns.boxplot(data=all_lasts, x="run_id", y="final_price")
sns.scatterplot(data=actual_prices, x="run_id", y="actual_price", zorder=10)
plt.ylim([0, 6])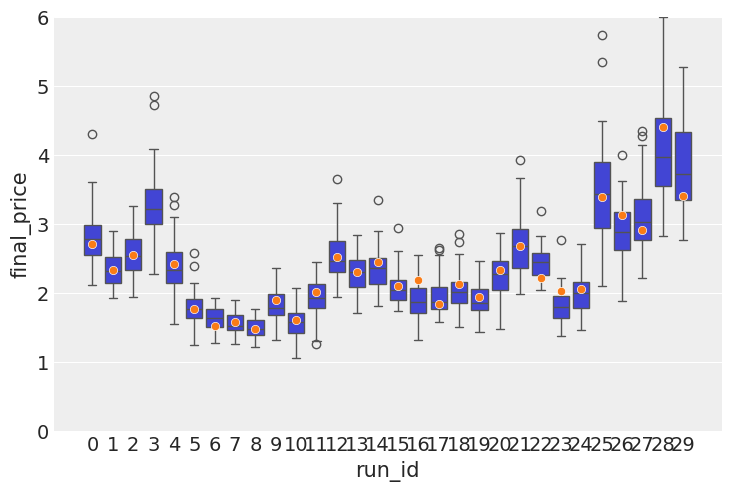
We can finally see that the mean error on the observed values is 25% lower than in the previous version.
all_lasts.join(
actual_prices, left_on="run_id", right_on="run_id", how="left"
).with_columns(error=(pl.col("final_price") - pl.col("actual_price")) ** 2).group_by(
"run_id"
).agg(pl.col("error").mean())["error"].median()0.08732833325394218Option pricing
Next, we calculate the call option payoff distributions, as well as model-implied option prices.
last_prices = (
all_runs.sort("date") # Ensure dates are in correct order
.group_by("run_id")
.agg(pl.col("price").last()) # Get the last price for each run
.rename({"price": "final_price"})
)
sns.histplot(last_prices, x="final_price")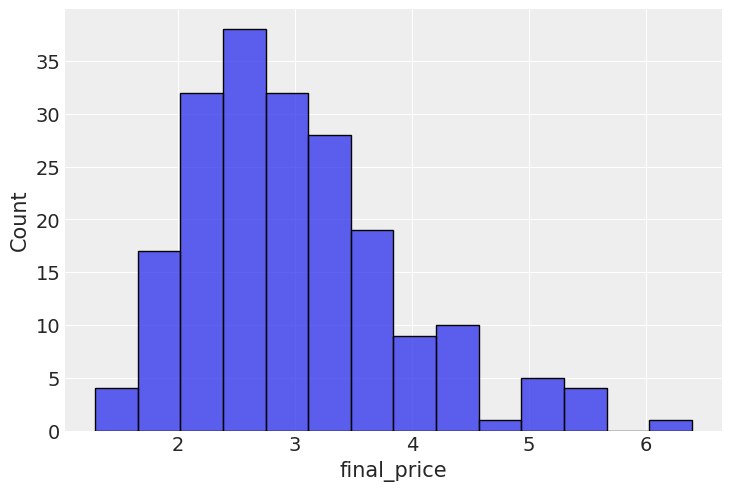
strike_prices = [2.5, 3.0, 3.5, 4.0]
# Create a list of DataFrames, one per strike
payoff_dfs = [
last_prices.with_columns(
payoff_at_expiry=(pl.col("final_price") - strike).clip(0),
strike=pl.lit(strike), # so we can track which row belongs to which strike
)
for strike in strike_prices
]
# Concatenate into one big DataFrame
payoff_df_all = pl.concat(payoff_dfs)
plt.figure(figsize=(12, 6))
sns.histplot(
data=payoff_df_all,
x="payoff_at_expiry",
hue="strike",
element="step",
stat="count",
bins=40,
)
plt.title("Call Option Payoff Distribution at Expiry")
plt.xlabel("Payoff at Expiry")
plt.ylabel("Count")
plt.grid(True)
plt.show()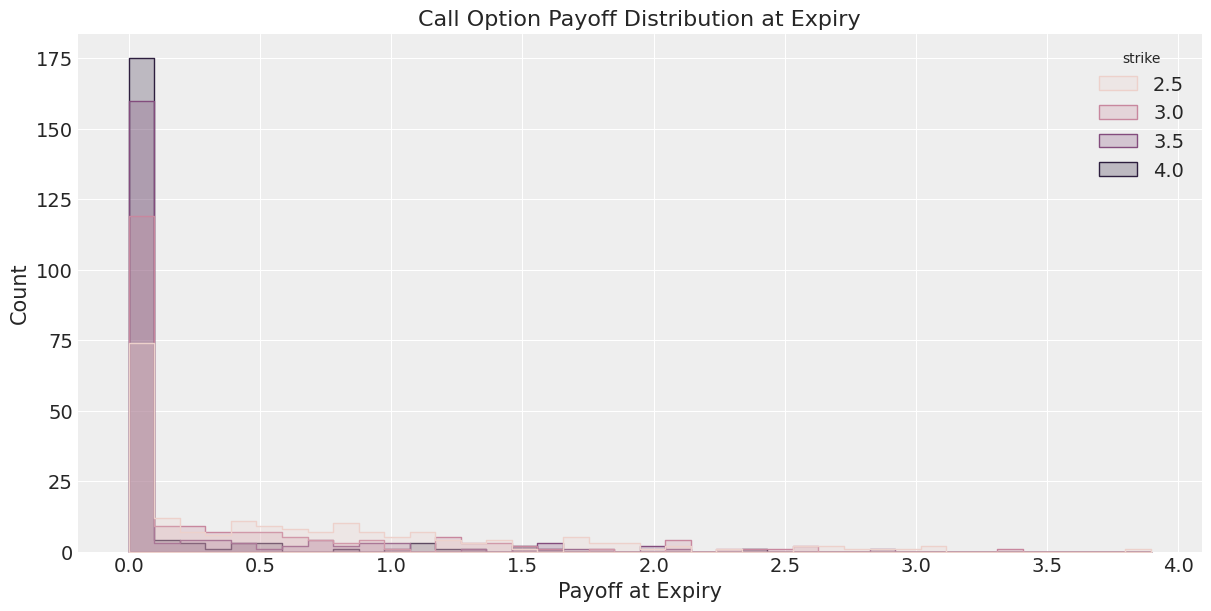
# Group and average payoff per strike
implied_prices = payoff_df_all.group_by("strike").agg(pl.col("payoff_at_expiry").mean())
# Plot the pricing curve
plt.figure(figsize=(10, 5))
sns.lineplot(data=implied_prices, x="strike", y="payoff_at_expiry", marker="o")
plt.title("Model-Implied Call Option Prices vs Strike")
plt.xlabel("Strike Price")
plt.ylabel("Fair Price (Expected Payoff)")
plt.grid(True)
plt.show()
In this post I have implemented a latent volatility model, which has a measurable improvement in predictive power for future price scenarios. In the next post I will demonstrate how energy commodities storage levels can be incorporated into this model.
Limitations & Next Steps
- The model assumes latent volatility follows a stationary process, which may not hold in extreme market events.
- Does not yet incorporate external factors (e.g., inventory levels, macro data).
- Model not benchmarked against market-implied volatility surfaces.
- Future work: extend to multivariate commodities or test on real-world options datasets.
- This is a research-grade toy model; do not use for actual trading decisions.